solarni.us blog

Fighting cNFT Spam on Solana
How I built cnft-spam-filter, an open-source spam filter for cNFTs on Solana with a 96% accuracy rate.
Published Feb 5, 2024 by @solarnius for the Solana Scribes hackathon, project for the cHack hackathon.
Contents
- Understanding the Problem
- Outlining a Good Solution
- Characteristics of Spam NFTS
- The Solution
- Benchmarks
- Conclusion
- Acknowledgements
1. Understanding the Problem
Spammers and scammers are heavily polluting the Solana ecosystem right now. They are creating cNFTs with misleading names and images and sending them out en masse to try to catch unsuspecting users.
This is extremely annoying as it results in wallets being full of scammy NFTs. While there are some attempts at a wallet-level to filter these NFTs out, they are unfortunately not very effective thus far.
Let's take a look at how these cNFTs are sent out. On Jan 29, I received the following cNFT:
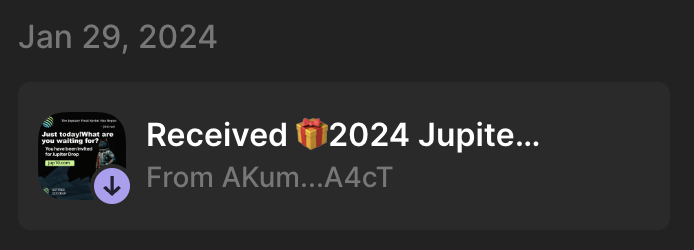
This cost the scammer 0.000005 SOL, or $0.0000013 at the time of writing. Let's look at the Merkle tree that this cNFT is a part of:
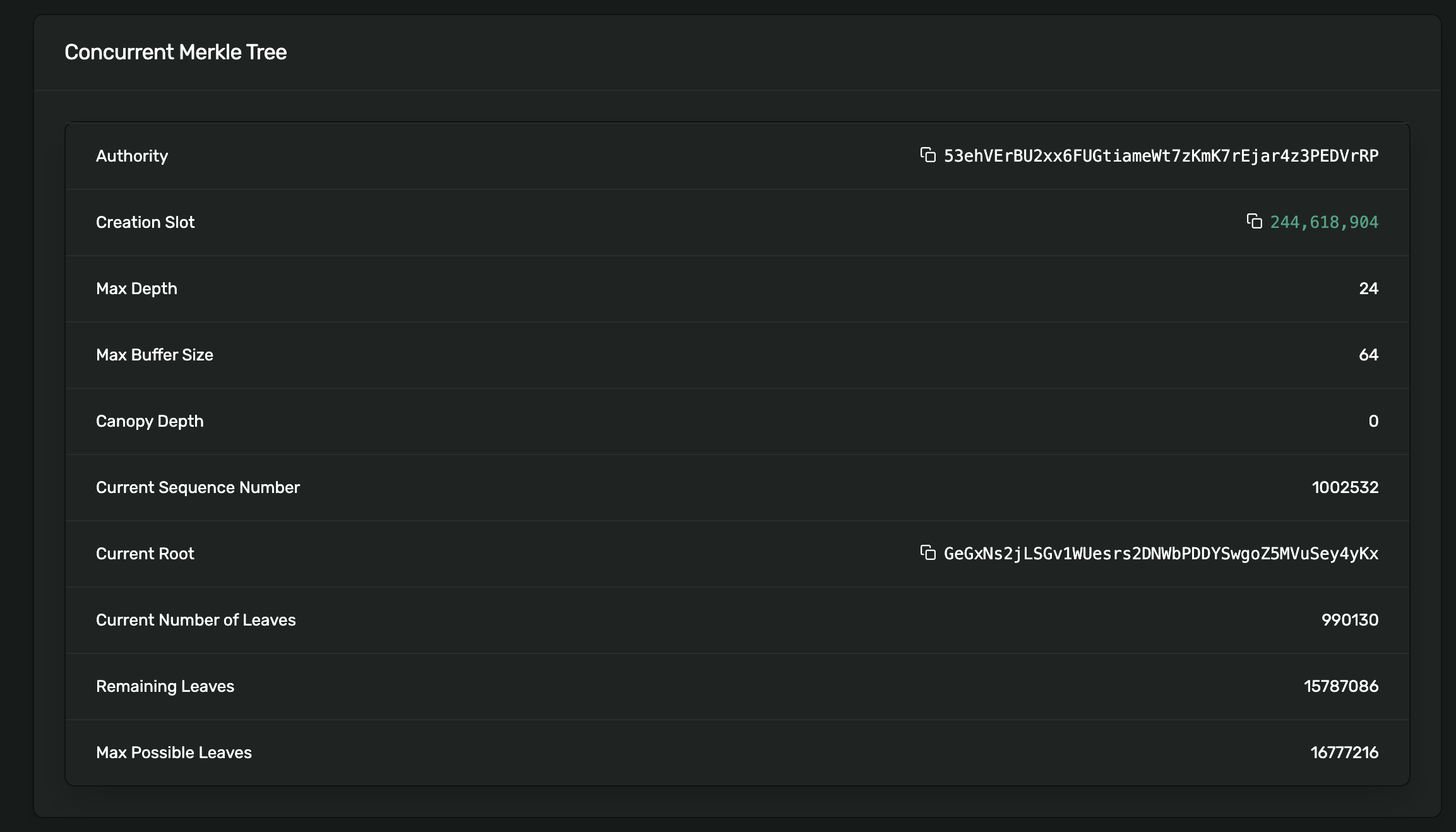
With a depth of 24 and a max buffer size of 64, this tree can hold 16.7 million cNFTs. So far, it's transferred about 1 million. What is especially annoying about this configuration is that the assets are actually not transferrable or burnable without using bespoke tools like solincinerator.

So, these cNFTs just accumulate in wallets, crowding out legitimate airdrops and NFTs and being generally really annoying. While it is a good thing that it's possible to send out so many assets for cheap, we need better ways to clearly demarcate spam assets from legitimate assets.
This is a problem that has been solved before. Email had the exact same issue: it's very cheap to send an email, and spammers take advantage of this to send out scams en-masse.
Some people have suggested that the solution to spam is to introduce constraints at the RPC or protocol level about who should be allowed to mint assets: whitelists, etc. This is a bad and scary idea. The whole point of a blockchain is that there is no authority that can tell you who can and cannot write to it.
The solution is therefore at the app level: to create filters that can identify spam/scam assets and filter them out. This project is an approach at creating such a filter.
2. Outlining a Good Solution
Before we can attempt to build a solution, we must first outline what a good solution would look like. A good solution to this problem is:
- Open-source, so we don't have to rely on a centralized arbiter of what is spam and what isn't
- Portable, so it can be used by many apps in different environments (server, serverless, browser, etc.)
- Fast, so user experience is not affected very much
- Accurate, so legitimate NFTs are not marked as spam and illegitimate NFTs are not marked as safe
3. Characteristics of Spam NFTS
To begin, let's consider what characteristics we can use to differentiate between safe and spam NFTs.
- URL in the image: almost always spam.
- Emoji in the name: usually spam.
- Image contains voucher/claim/award/scammy text: almost always spam.
- cNFT is untransferrable: almost always spam.
In general, these characteristics fall under two categories: the "eye test" of whether the image/text looks scammy, and the "on-chain test" of whether the asset seems at all legitimate.
Therefore, our system will use a combination of these two categories of factors in order to classify cNFTs as legitimate or not.
4. The Solution
Introducing: cnft-spam-filter, an open-source, lightweight, portable, and fast spam filter for cNFTs that I wrote over the past few days.
Here it is running entirely in the browser from a random selection of my cNFTs:
If you're a developer, you can follow the instructions on the repo to get started using it. In the rest of this article, I'll explain how I designed the filter and go over some benchmarks for its performance.
The library is broken up into two main functions: extractTokens and classify.
extractTokens

In order to classify a cNFT as spam or ham (not spam), we must first be able to describe the cNFT. To do so, we generate a list of tokens from its on-chain metadata and from running its image through Optical Character Recognition (OCR).
The tokens returned by extractTokens roughly correspond to the characteristics of spam cNFTs we outlined above. We detect links in the image, emojis in the name, whether the tree depth makes burning it hard, and all of the scammy text in the image.
classify

Once we have described the cNFT, we can classify it as either "spam" or "ham" using a model that I trained on a hand-labeled set of scam and legitimate cNFTs.
The model is a naive bayesian classifier that uses the tokens generated by extractTokens. Basically, it considers the posterior probability that a cNFT is spam given the tokens that represent it, knowing the prior probability and the likelihood (where the likelihood is learned by model training).
In laymans terms: the classifier is trained on a bunch of spam and ham data and then compares a piece of new data to what it knows. It just tells you whether the new data looks more like spam or more like ham.
It's not guaranteed to be accurate, but it is generally pretty good.
5. Benchmarks
When embarking on this project, I set out a few criteria for what a good solution would look like:
- Open-source
- Portable
- Fast
- Accurate
This library meets all of these criteria.
Open-source
All code is released on GitHub under the MIT license, as well as all training data and the code for training a model. You can modify this code and use it however you want with or without attribution. As open-source as open-source gets.
Portability
I've put together examples in the GitHub directory of the library functioning in three different environments: on a server, in a serverless lambda function, and in the browser.
This library is extremely portable, so developers can use it wherever makes sense for their application. If you run a high-performance app like an NFT exchange, you probably want to host it on your own server. If you run a wallet, you might consider running it on the client. And if you run an indexer or are doing stats, you might want to use a lambda function. It's up to you: the library will work in all of these environments (with varying speeds based on system resources).
Speed
Speed is probably the weakest point of this library. It takes about 1 second for most cNFTs, but can take up to 10 seconds with weird images--mostly in the OCR. There are definite improvements to be made here, but it's usable for now.
Speed trace (in MS) of a slow run:
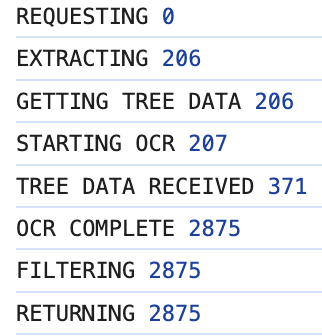
Speed trace (in MS) of a fast run (note how much quicker OCR is):
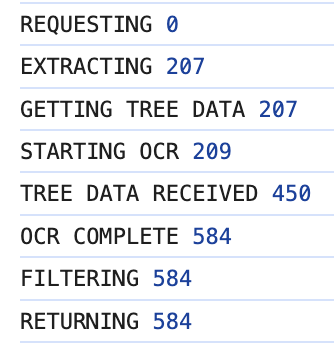
Given that we have to make two consecutive RPC calls, the lower limit on speed is about 400ms. The most obvious way to improve our current speed is to add a layer that downloads the image and resizes it before doing OCR, as the slow calls are generally on large files. This is a future improvement: feel free to add it yourself!
Accuracy
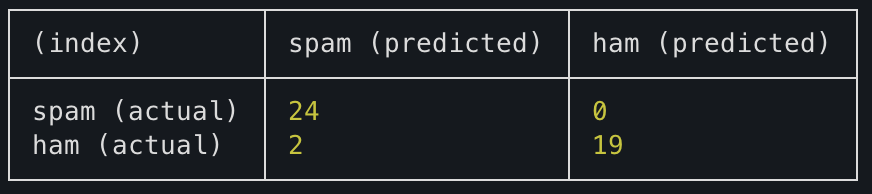
I've prepared a test set with cNFTs picked from my wallets including spam and ham cNFTs. The confusion matrix for the library is shown above. The sample size is pretty small, so please submit your spam and legitimate assetIds so that I can improve the training and the test sets!
It currently has an ~96% accuracy rate on the test set, which I'm really happy about!
Of course, the training and test sets are both really small right now and I expect performance to degrade significantly in the wild, especially as spammers catch on to spam detection techniques. Spam fighting is a constant battle, but this is a good start.
If you want to help, please consider taking some time to copy the assetIds of both legitimate and spam cNFTs and send them my way byopening a GitHub issue! It would save me a lot of work :D
6. Conclusion
This project has achieved what it set out to achieve: an accurate, fast, open-source spam filter for cNFTs that can be run on any device in any environment. Now it's time to get feedback from the ecosystem and get it out in the wild!
If you're a project maintainer and you want to use this filter and need help or custom features, feel free to hit me up on Twitter.
Hopefully, this project contributes something useful to the Solana ecosystem :) it was a lot of fun to make!
7. Acknowledgements
Big thanks to Metaplex for sponsoring cHack and giving me an opportunity to maybe win a prize for building a public good like a cNFT spam filter.
Big thanks to @LamportDAO, @heliuslabs, @SolanaCollectiv, and @SuperteamEarn for sponsoring the Solana Scribes hackathon and compelling me to write this accompanying article, as well as Stockpile Labs for sponsoring the Public Goods track.
Also thanks to Mert, pls gib funding now thx xdd